In the age of machine learning (ML), model deployment is not the finish line—it’s the starting point. Once models go live, they face real-world data drift, concept changes, scaling challenges, and unpredictable system behavior. Traditional DevOps practices aren’t enough to handle the complexity of continuously optimizing ML systems. This is where AI Ops—the application of AI to manage, optimize, and automate IT and ML operations—comes into play.
Even more powerful is the idea of a multi-agent AI Ops system: a collection of specialized agents, each with a defined role, that collaborates to monitor, diagnose, optimize, and adapt ML models autonomously. Instead of one monolithic automation script, multi-agent systems bring modularity, resilience, and flexibility.
In this blog, we’ll walk through:
- What a multi-agent AI Ops system is
- Why it’s critical for continuous ML optimization
- Core building blocks of such a system
- A step-by-step guide to designing and implementing it
- Best practices and future trends
What Is a Multi-Agent AI Ops System?
A multi-agent AI Ops system consists of autonomous AI agents working together, each responsible for a particular task in the ML lifecycle. These agents can communicate, coordinate, and take corrective actions—like digital co-workers.
For example, one agent might monitor real-time inference latency, another might detect model drift, another might trigger retraining, and yet another might validate and deploy the retrained model safely.
The system resembles a self-healing, self-optimizing loop, ensuring that ML models remain robust, efficient, and accurate without constant human intervention.
Why Do We Need Multi-Agent Systems for Continuous Optimization?
Deploying an ML model into production is notoriously fragile. A few common issues:
- Data drift: Input data distribution changes over time, breaking assumptions.
- Concept drift: The relationship between features and target evolves (e.g., customer behavior shifts).
- Infrastructure scaling: Demand spikes cause bottlenecks in inference pipelines.
- Model degradation: Accuracy drops gradually without obvious failures.
- Operational overhead: Teams spend countless hours manually retraining, debugging, and redeploying.
A multi-agent system helps address these pain points by enabling:
- Parallelism: Multiple tasks (monitoring, retraining, scaling) handled simultaneously.
- Specialization: Each agent focuses on one domain (metrics, drift, deployment).
- Autonomy: Reduced need for human babysitting.
- Adaptability: Faster response to system or data changes.
Core Building Blocks
To design such a system, think in terms of agents and their roles, plus the infrastructure to enable coordination.
Key Agents
- Monitoring Agent – Tracks latency, throughput, error rates, hardware usage, and business KPIs.
- Drift Detection Agent – Compares real-time data distributions with training data to detect shifts.
- Performance Evaluation Agent – Continuously benchmarks predictions against ground truth (when available).
- Retraining Agent – Decides when to initiate retraining and selects appropriate data slices.
- Deployment Agent – Validates new models, runs A/B or shadow tests, and rolls out updates.
- Scaling Agent – Adjusts infrastructure dynamically for cost and performance optimization.
- Knowledge Agent – Maintains logs, insights, and feedback loops to improve future operations.
Infrastructure Enablers
- Message Bus (e.g., Kafka, RabbitMQ): For agent-to-agent communication.
- Model Registry (e.g., MLflow, Vertex AI, SageMaker): Stores model versions and metadata.
- Feature Store: Provides consistent feature definitions across training and inference.
- Monitoring Stack (Prometheus, Grafana, ELK): Aggregates system and model-level metrics.
- Policy Engine: Encodes guardrails (e.g., rollback if accuracy drops by >5%).
Step-by-Step Guide to Building the System
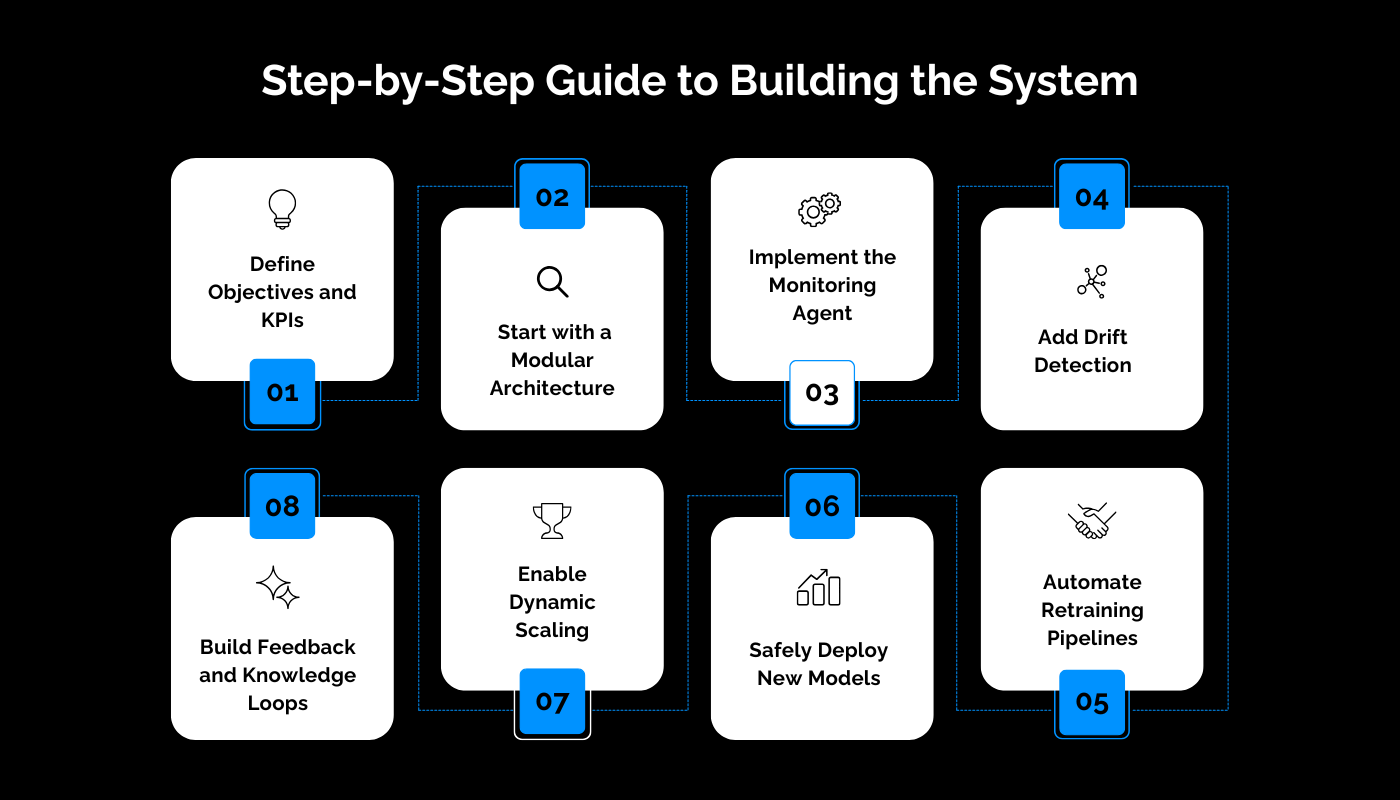
Step 1: Define Objectives and KPIs
Decide what “continuous optimization” means in your context. Common KPIs include:
- Prediction accuracy or business-specific metrics (e.g., churn reduction).
- Latency and throughput targets.
- Cost-efficiency of compute resources.
- Regulatory compliance and fairness metrics.
Step 2: Start with a Modular Architecture
Design the system around microservices or containerized agents (using Docker + Kubernetes). Each agent should expose APIs or subscribe to event streams for coordination.
Step 3: Implement the Monitoring Agent
This is the foundation. Set up pipelines to collect:
- Model-level metrics (accuracy, precision/recall, calibration).
- Data-level metrics (distribution stats, missing values).
- System-level metrics (CPU/GPU utilization, latency).
- Feed these metrics into a centralized dashboard.
Step 4: Add Drift Detection
Integrate statistical tests (e.g., KL divergence, Population Stability Index) or ML-based detectors to flag distributional changes. Make sure drift alerts are contextualized (is drift significant enough to matter?).
Step 5: Automate Retraining Pipelines
The Retraining Agent should:
- Pull fresh data samples.
- Trigger pipelines (e.g., via Kubeflow, Airflow, or Prefect).
- Run feature engineering, model training, and validation.
- Compare new models against baselines.
Step 6: Safely Deploy New Models
The Deployment Agent must ensure safe rollouts:
- Shadow deployment (new model runs silently in parallel).
- Canary release (gradually increase traffic).
- Automatic rollback if KPIs regress.
Step 7: Enable Dynamic Scaling
The Scaling Agent can leverage Kubernetes autoscaling or custom logic to manage compute resources. It balances cost against SLA commitments.
Step 8: Build Feedback and Knowledge Loops
The Knowledge Agent ensures every event—drift, retrain, deployment—is logged and contextualized. Over time, the system learns policies (e.g., retraining is often needed after a holiday sales spike).
Best Practices
- Human-in-the-Loop Control: Keep humans in the approval path for high-stakes updates (finance, healthcare).
- Guardrails and Policies: Explicitly encode rollback criteria and safety checks.
- Scalability First: Design with distributed infrastructure to handle spikes.
- Observability Over Monitoring: Collect rich logs and traces, not just metrics.
- Continuous Learning for Agents: Agents themselves should improve based on historical outcomes.
Future Trends
The field of AI Ops is rapidly evolving, and multi-agent systems will only grow more sophisticated. Expect to see:
- LLM-powered agents that can reason over logs, anomalies, and even code fixes.
- Self-supervised drift detection that doesn’t rely on labeled data.
- Cross-organization knowledge sharingwhere agents learn from industry-wide patterns.
- Edge AI Ops systems for continuous optimization on IoT devices.
Conclusion
Building a multi-agent AI Ops system for continuous ML optimization isn’t just a technical challenge—it’s a mindset shift. Instead of one-off fixes and manual monitoring, you create a living, adaptive ecosystem of specialized agents.
The payoff is immense: faster adaptation to data shifts, reduced downtime, improved accuracy, and lower operational costs. In essence, you move closer to the holy grail of AI: models that don’t just perform well today but continuously evolve to stay relevant tomorrow.




