In today’s data-driven world, Artificial Intelligence (AI) holds the potential to transform industries, solve complex problems, and drive innovation. But like any high-performance engine, AI systems rely on high-quality fuel, and in this case, that fuel is data. The adage “garbage in, garbage out” has never been more relevant. Poor data quality can derail even the most sophisticated machine learning models, leading to biased predictions, flawed insights, and costly mistakes.
So, what does it mean to ensure data quality? It’s not just about having data, it’s about having clean, consistent, and reliable data. And that’s where the art (and science) of data profiling, cleansing, and validation comes into play.
Data Profiling: Understanding Before You Transform
Before you clean or validate data, you need to understand it. That’s the job of data profiling — the process of examining data from existing sources and summarizing information about it.
Think of data profiling as a diagnostic step. It helps you uncover:
- Patterns and statistics — mean, median, frequency distributions, etc.
- Anomalies — missing values, outliers, unusual formats.
- Inconsistencies — mismatched schemas, unexpected data types, or relationships.
For example, if you’re building a customer churn prediction model, profiling your customer database might reveal that 15% of the ‘Last Purchase Date’ fields are null, a problem that needs resolution before feeding it into the model.
Profiling tools (often integrated into modern ETL/ELT platforms) give data engineers a bird’s-eye view of the dataset, allowing them to spot red flags early in the pipeline.
Data Cleansing: The Refinement Process
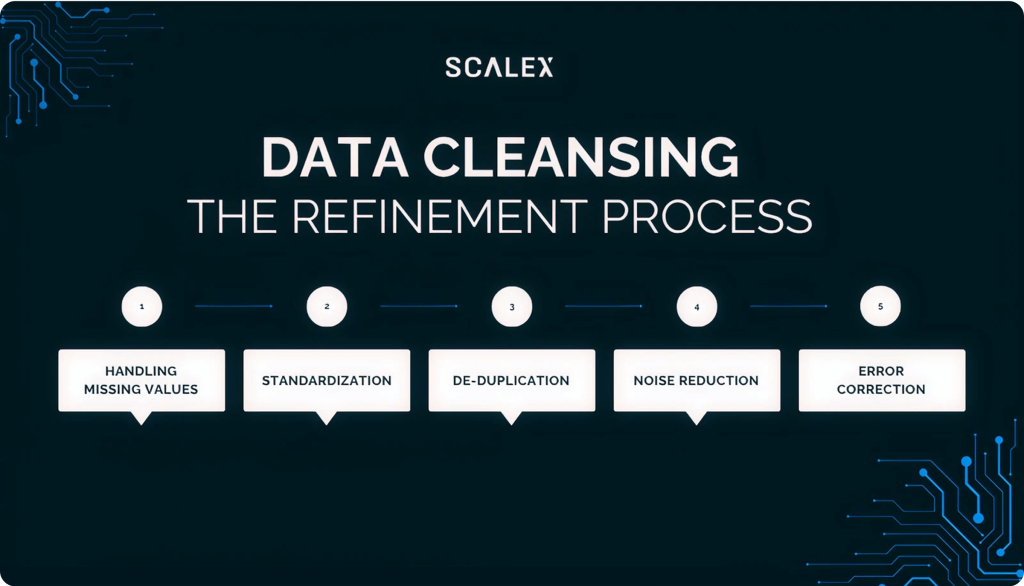
Once you’ve profiled your data, the next step is data cleansing, the process of correcting or removing inaccurate, incomplete, or irrelevant data. It’s like refining crude oil into high-octane fuel.
Cleansing involves multiple techniques:
- Handling missing values: Imputation, deletion, or flagging.
- Standardization: Ensuring consistent formats for dates, addresses, phone numbers, etc.
- De-duplication: Removing or consolidating duplicate records.
- Noise reduction: Identifying and filtering outliers or irrelevant data.
- Error correction: Fixing typos or invalid entries using reference datasets or rules.
Effective cleansing not only improves model accuracy but also reduces training time and costs. More importantly, it boosts stakeholder trust, clean data tells a consistent and truthful story.
Automation plays a huge role here. Leveraging cleansing frameworks within data pipelines ensures repeatability, scalability, and governance, especially in environments dealing with streaming or big data.
Data Validation: Trust Through Verification
Data validation is the final checkpoint before data flows downstream into analytics or machine learning models. It answers one critical question: Can this data be trusted for its intended use?
Validation rules may include:
- Schema checks: Verifying that fields are present and of the correct type.
- Range checks: Ensuring numeric values fall within expected boundaries.
- Business rule enforcement: For instance, a loan application must have a credit score above a minimum threshold.
- Cross-field validation: Dates should make logical sense, e.g., ‘Order Date’ can’t be after ‘Delivery Date’.
Automating validation in your data pipelines prevents broken or corrupt datasets from entering your AI workflows. It also ensures that models don’t “learn” from flawed or biased data.
Continuous validation, especially in dynamic environments like streaming data pipelines, allows organizations to monitor for data drift, schema changes, and anomalies in real-time.
The Power of Seamless Pipelines
Today’s AI success hinges not just on smart algorithms but on robust data engineering. Data profiling, cleansing, and validation aren’t just isolated tasks — they are integral steps in end-to-end pipelines that feed the AI engine.
Modern data pipelines, powered by tools like Apache Airflow, dbt, or cloud-native services, enable teams to automate, monitor, and orchestrate these steps seamlessly. When done right, this results in:
- Faster experimentation with ML models.
- Higher model accuracy and reliability.
- Streamlined compliance with data governance standards.
- Better alignment between business teams and data scientists.
In short, clean data makes AI work better, and smarter.
Ready to Elevate Your Data Quality Game?

At Scalex, we understand that high-quality data is the lifeblood of successful AI and analytics initiatives. That’s why our data engineering solutions are built to help you profile, cleanse, and validate your data, end to end.
Whether you’re building your first AI pipeline or scaling complex, real-time models across departments, Scalex enables you to trust your data and accelerate your outcomes.
Let’s connect and show you how we can transform your data into your biggest asset.




